A data platform like Sidra can become the nerve center of a broader digital transformation strategy by providing a unified foundation for managing, integrating, and leveraging data across the organization.
Digital transformation is a necessity, not a trend, but an essential evolution. Companies across all industries are adopting digital technologies to survive, compete, and lead. The key is to use technology as an enabler of change, not as an end in itself.
Sidra Data & AI Platform drives this transformation by providing a scalable, automated, and data-driven infrastructure. Its Platform as a Service (PaaS) architecture enables efficient management of large volumes of data while ensuring security, compliance, and operational agility.
More than just an analytical solution, Sidra optimizes data management and integration with critical business systems, enhancing decision-making and operational efficiency in highly regulated industries.
Sidra Data & AI Platform unifies and optimizes data management, enabling businesses to extract, validate, and integrate information from internal and external sources. With powerful processing capabilities, Sidra applies customized rules, algorithms, and automation to ensure data accuracy and reliability.
Unlike traditional platforms that enforce a single Golden Record at the data lake level, Sidra takes a more flexible approach. Instead of imposing a rigid, universal data version, Sidra delegates Golden Record management to its Data Products, allowing each data consumer to define their own rules based on specific business needs. This adaptability makes Sidra an ideal foundation for data mesh architectures, preventing the Golden Record from becoming a restrictive bottleneck.
Designed for scalability and compliance, Sidra empowers businesses to harness the full potential of their data with security, automation, and seamless integration.
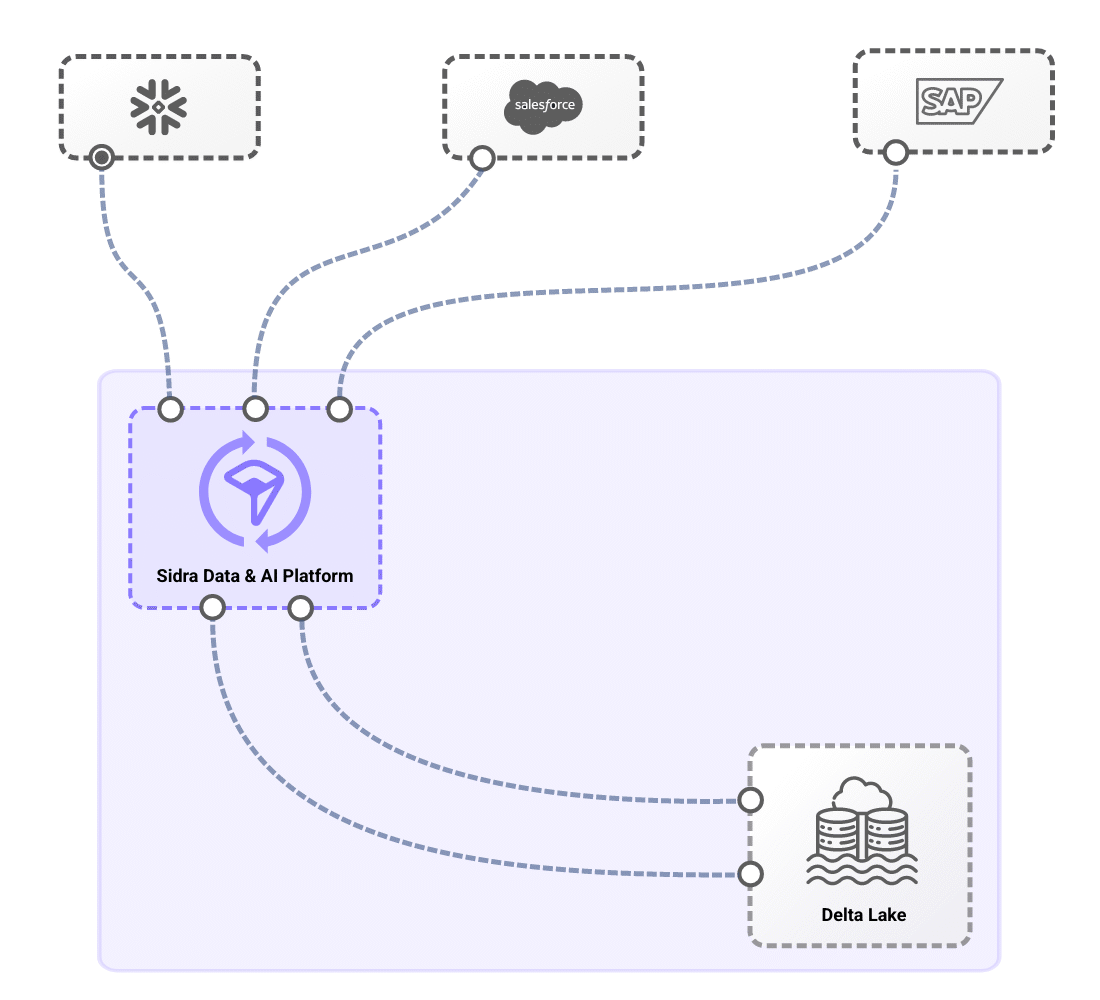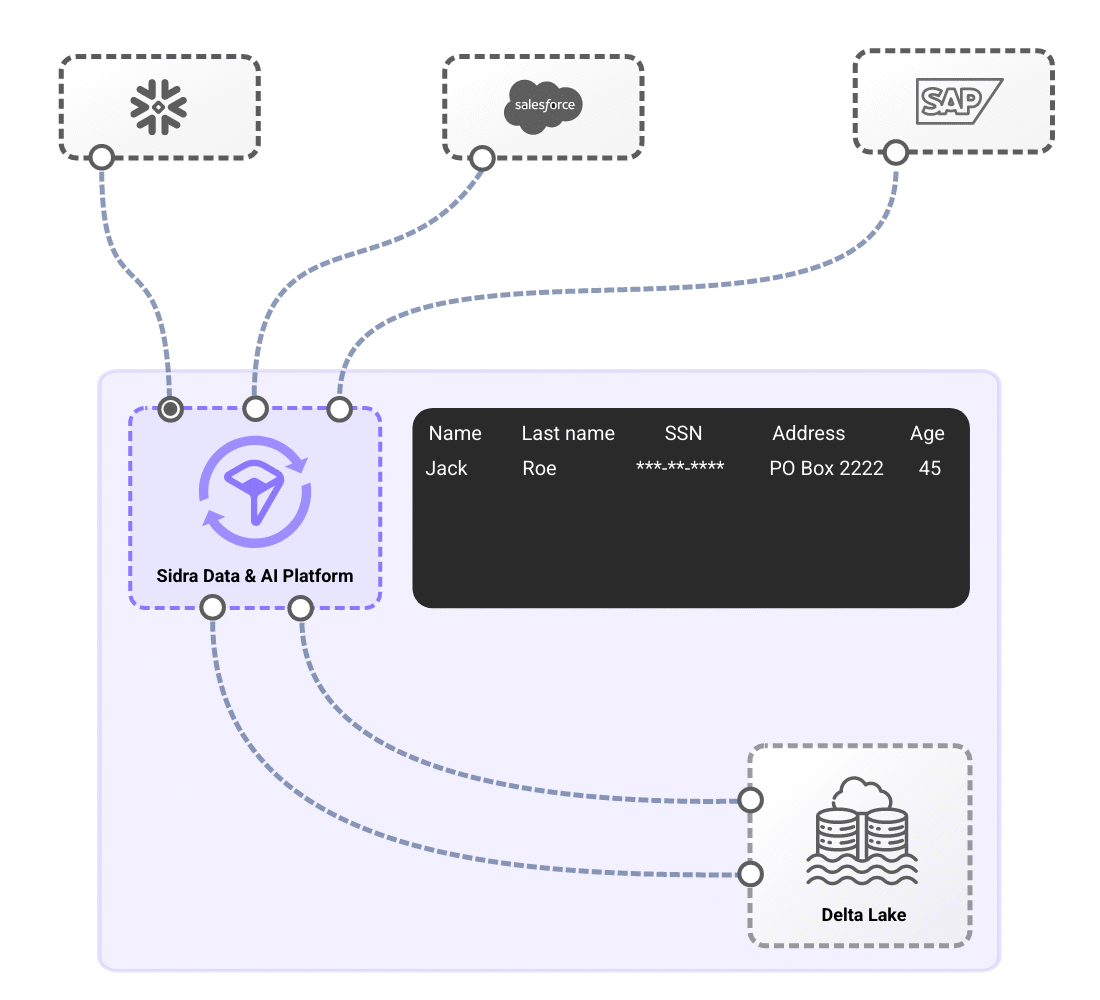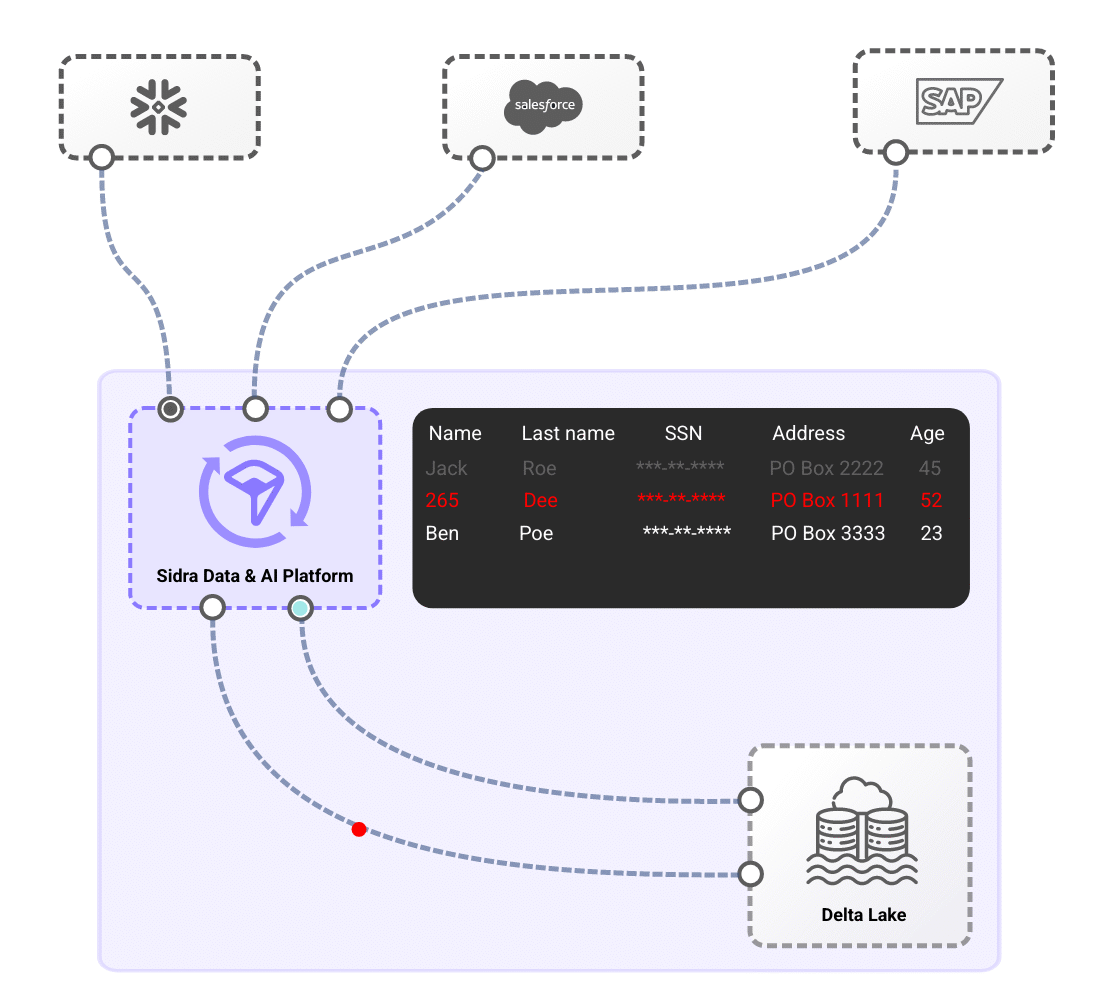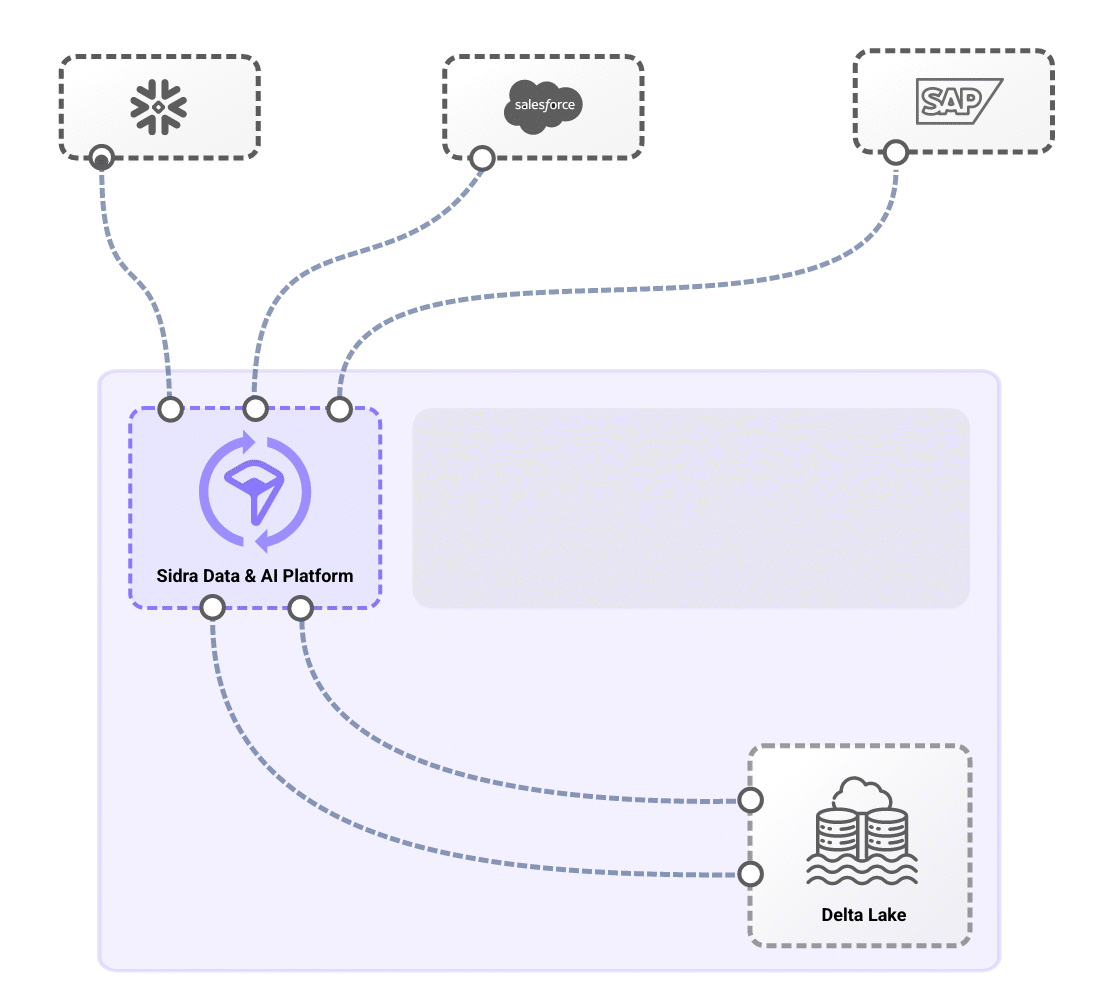
Experience effortless integration with your operational systems and business applications through Sidra Data & AI Platform. Automate data ingestion, ensure compliance, and streamline end-to-end workflows with pre-built connectors, self-managed data distribution, and intelligent schema evolution. With advanced AI-driven anomaly detection, governance frameworks, and real-time observability, Sidra enhances data reliability, accelerates transformation, and empowers teams with unparalleled efficiency. Unlock the power of scalable, secure, and automated data management—simplify complexity, maximize insights, and drive innovation with Sidra.
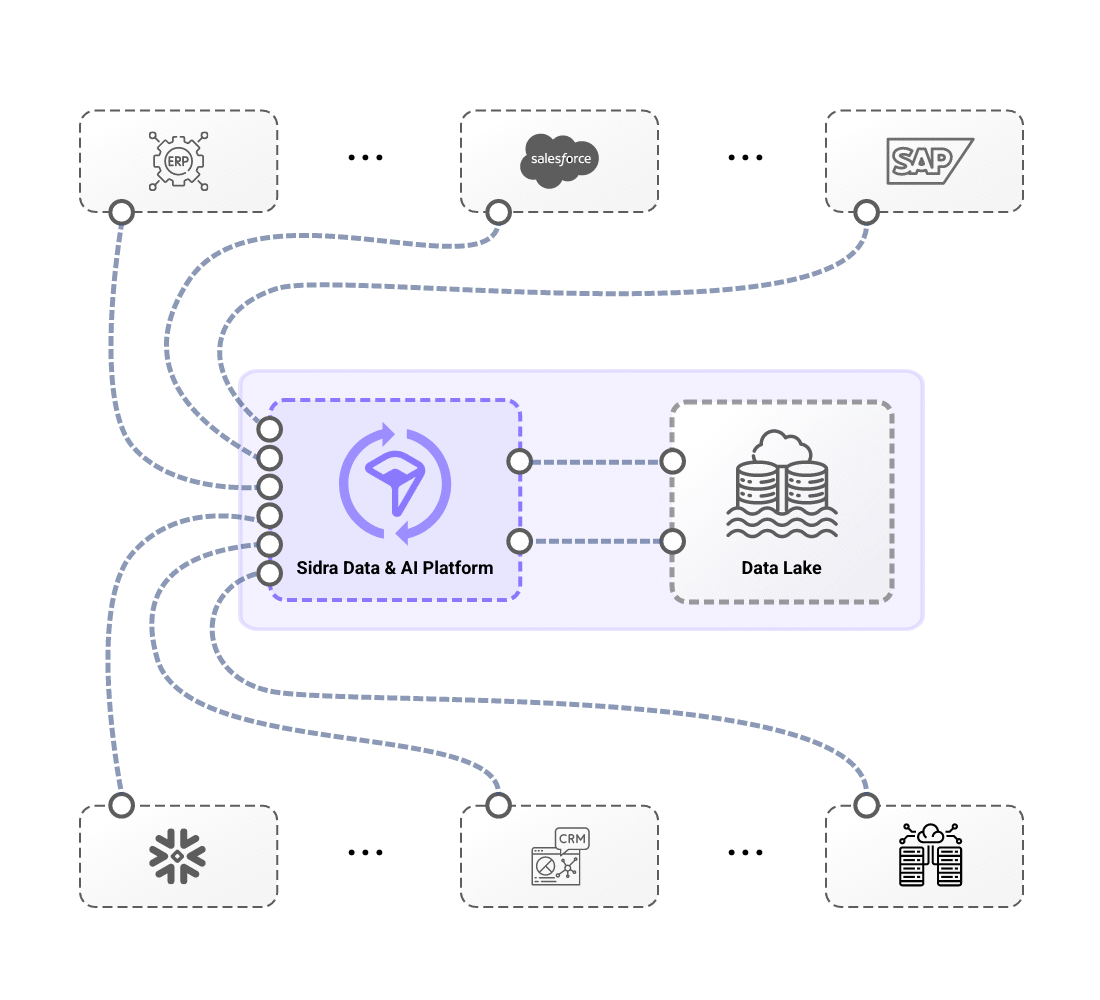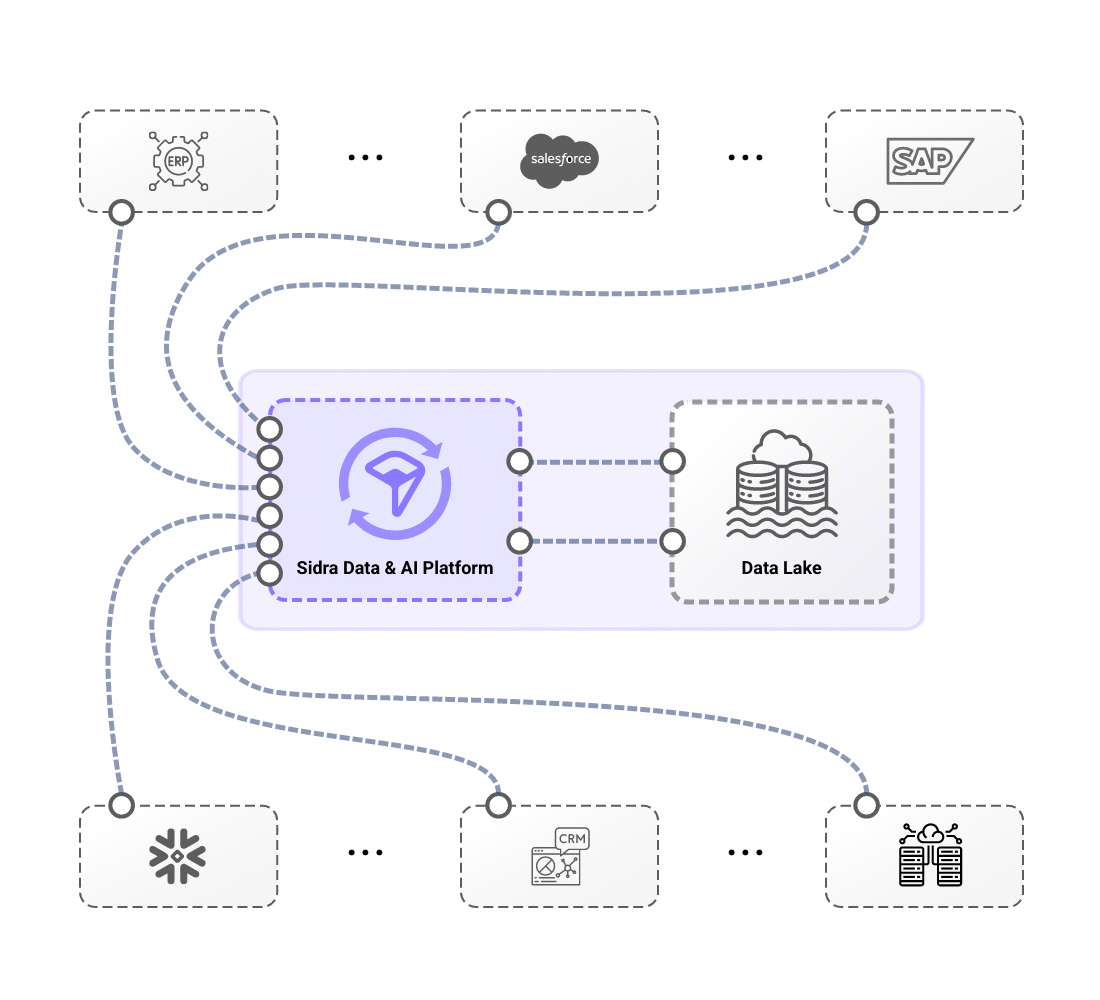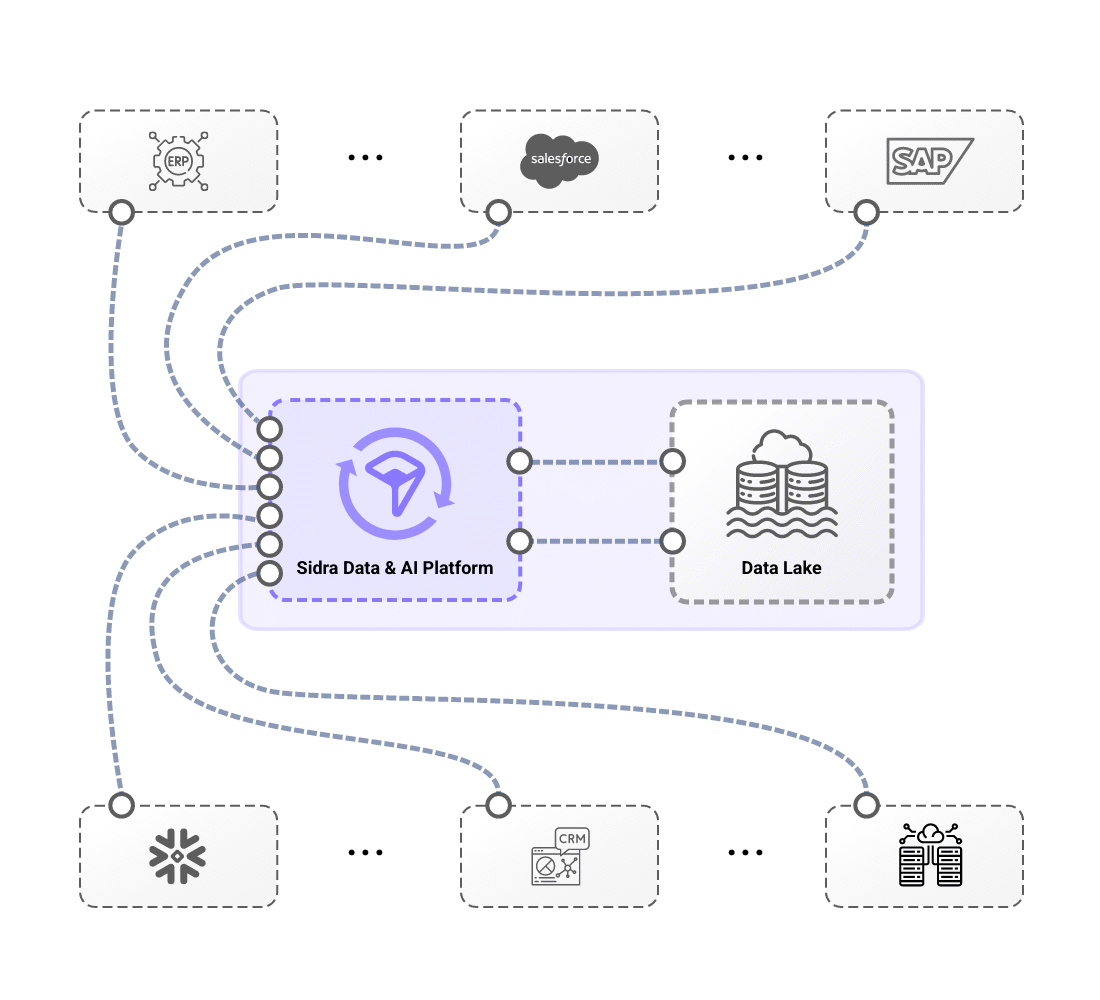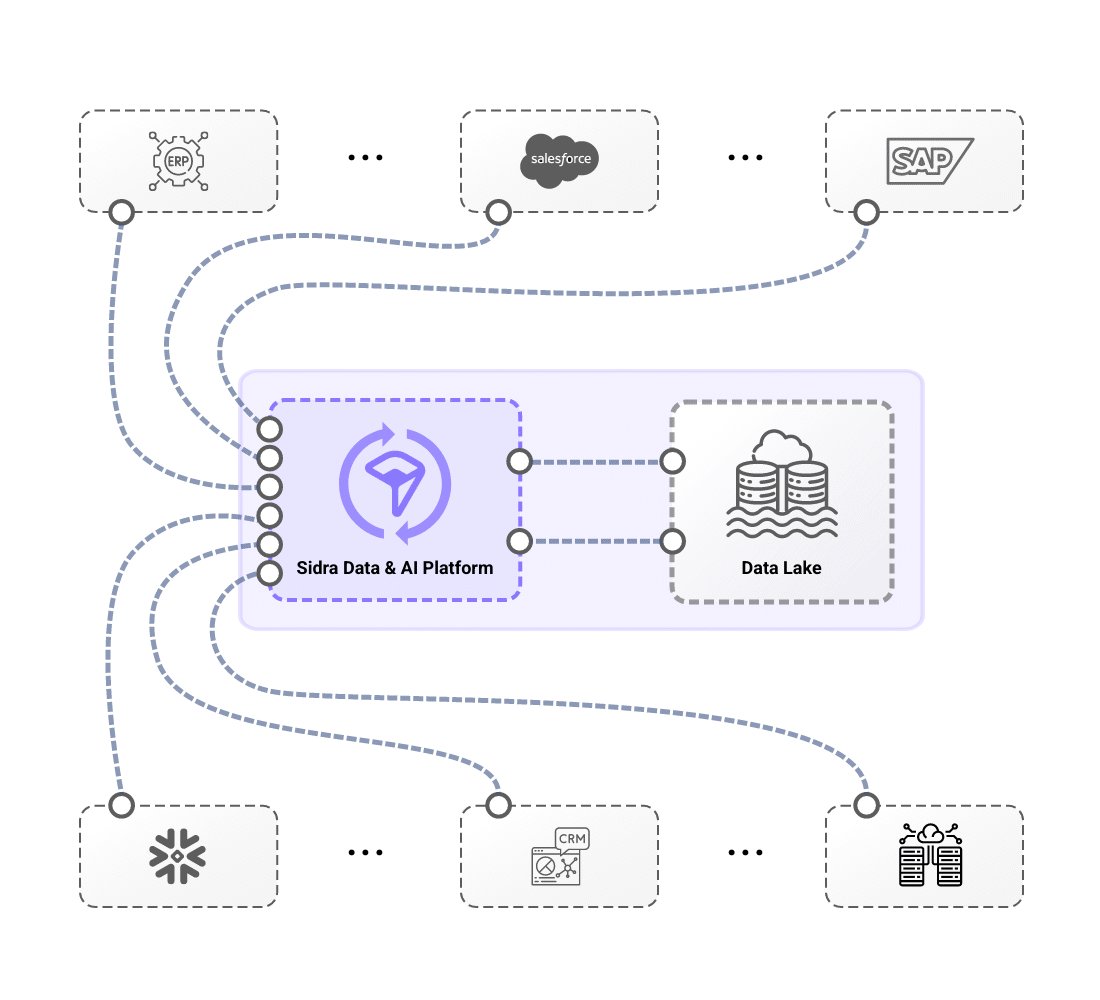
From automated ingestion from source systems through pre-built connectors to self-managed domain-oriented data distribution, end-to-end data flow is massively simplified.
Sidra simplifies data management through Core Services that orchestrate ingestion, processing, and automation. With minimal configuration, organizations can create fully automated data pipelines that handle schema evolution, PII detection, and technical validations, ensuring seamless and secure data flow. Once configured, each data load undergoes automated verification processes, including Anomaly Detection, allowing operators to proactively identify inconsistencies, improving data reliability and transparency with minimal effort. Additionally, schema evolution capabilities ensure that pipelines automatically adjust as source systems change, while generating metadata to support auditing and compliance requirements.
Sidra also streamlines data distribution with an automated reverse-ETL Synchronization approach, enabling teams to define what data to distribute and how through an intuitive UI, operating under a set-and-forget model. This allows multiple teams to access the same datasets independently, eliminating bottlenecks and avoiding inconsistencies from source-level changes. By leveraging these capabilities, Sidra ingests and processes vast amounts of data within hours, significantly reducing the complexity and time required compared to traditional solutions, while ensuring a highly scalable, efficient, and automated data ecosystem.
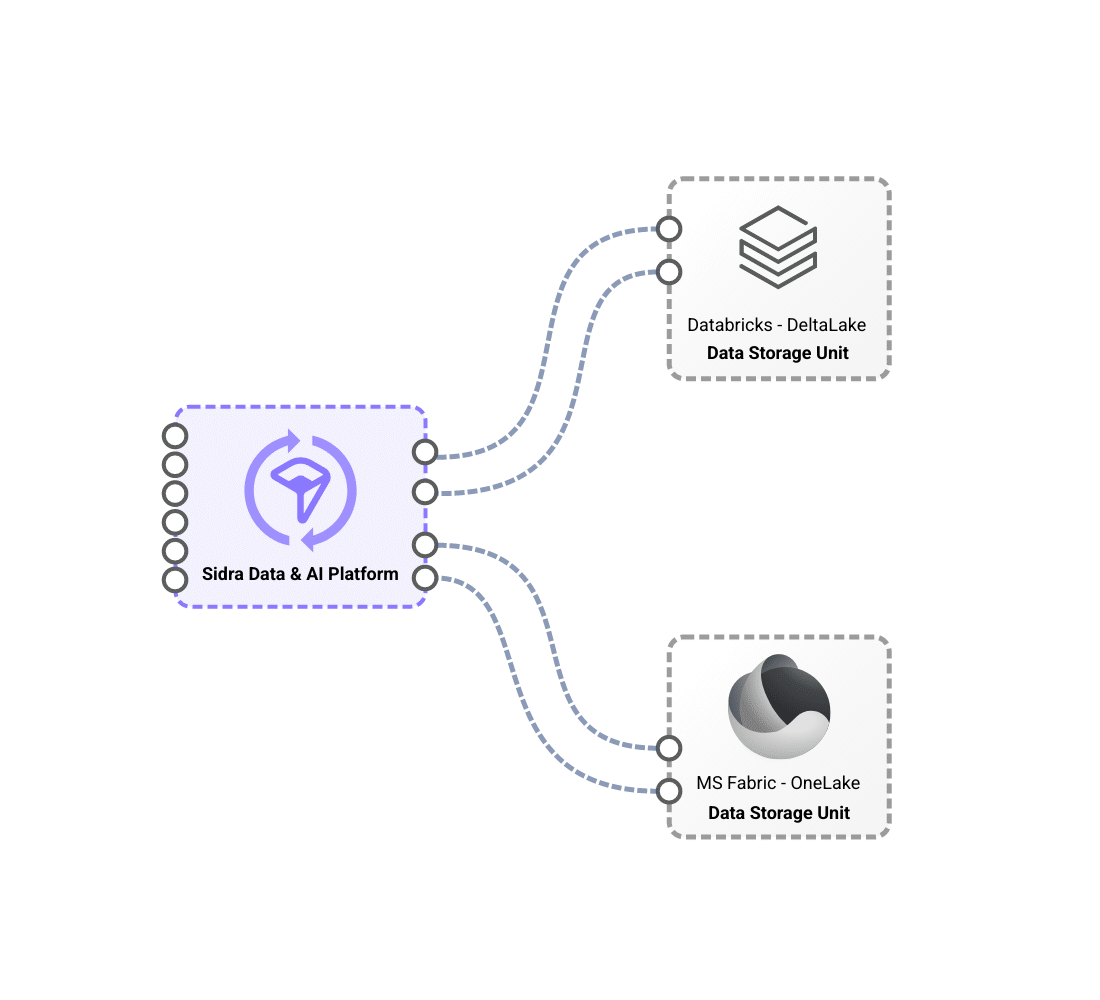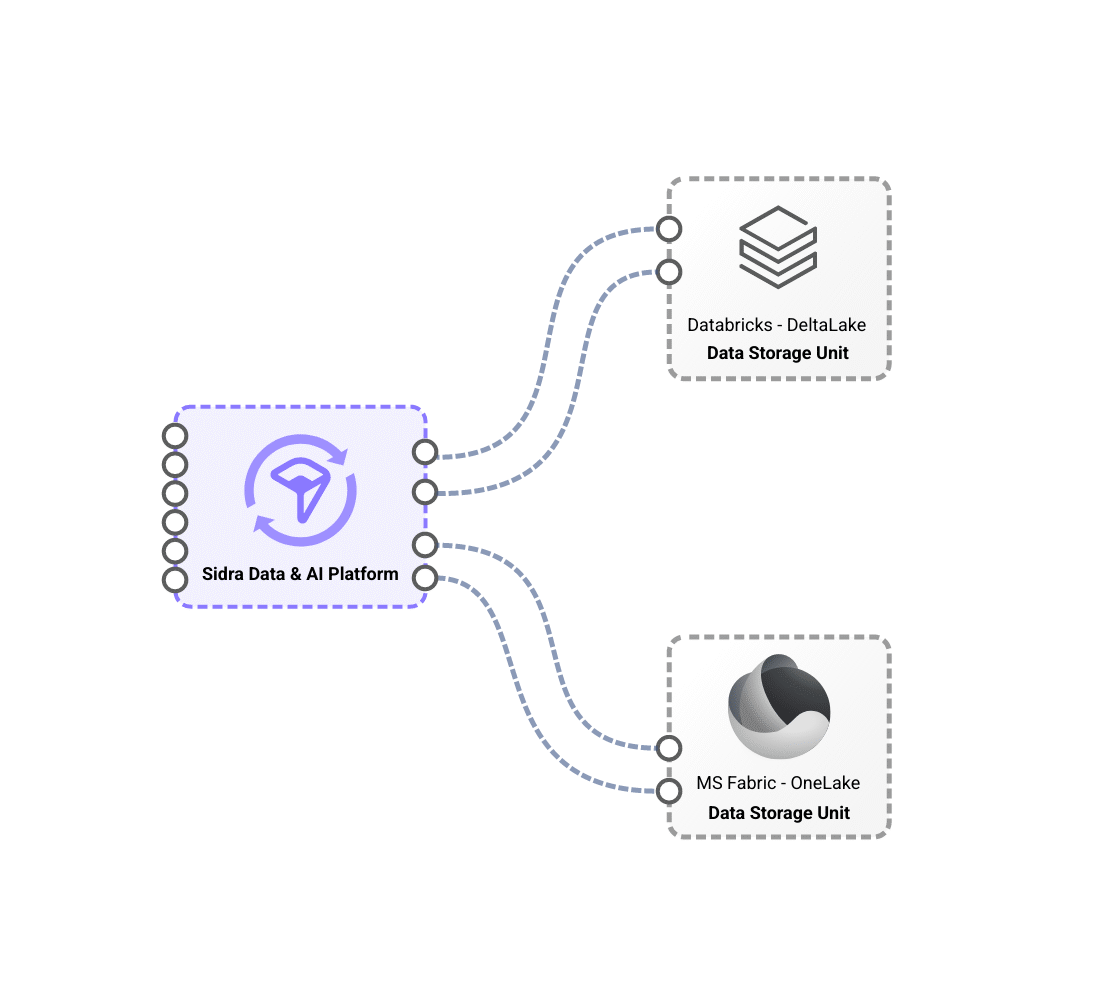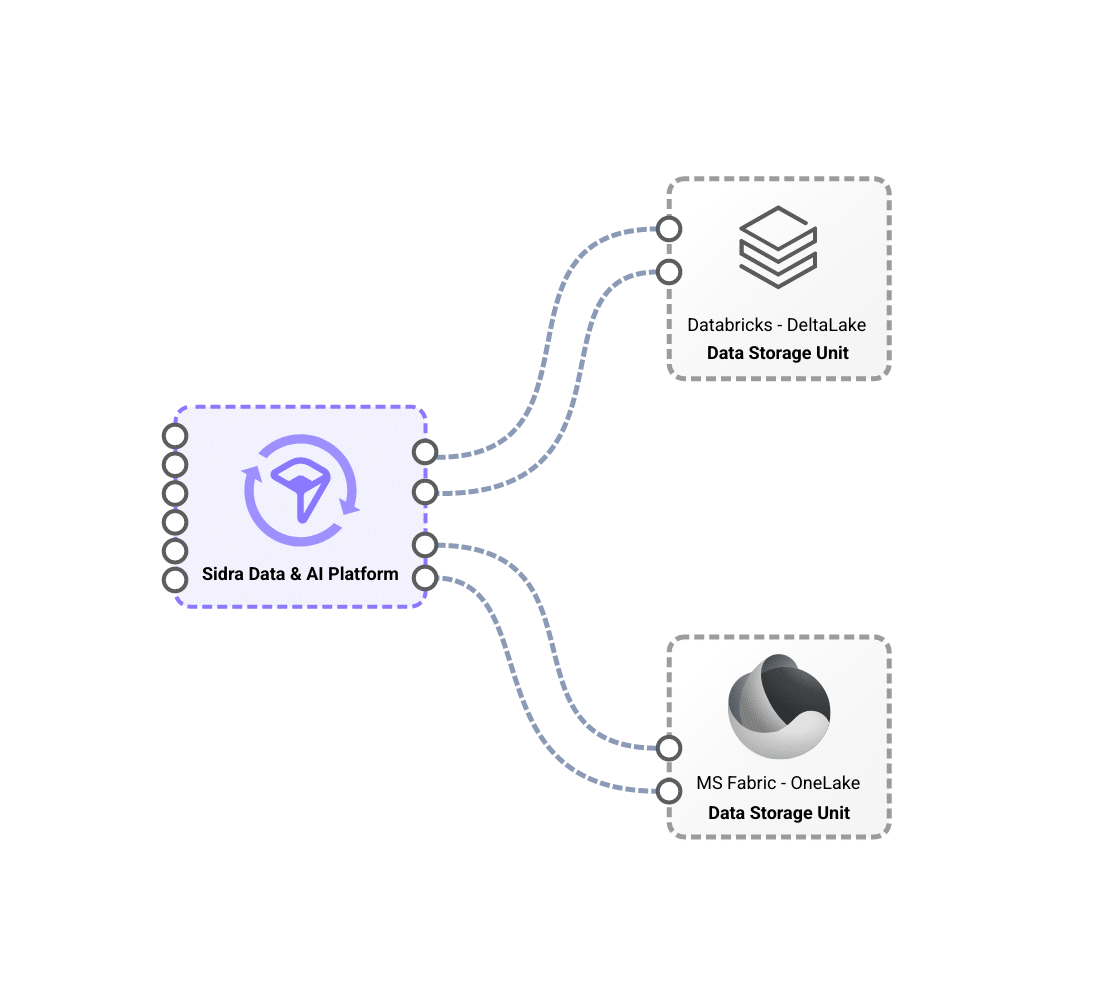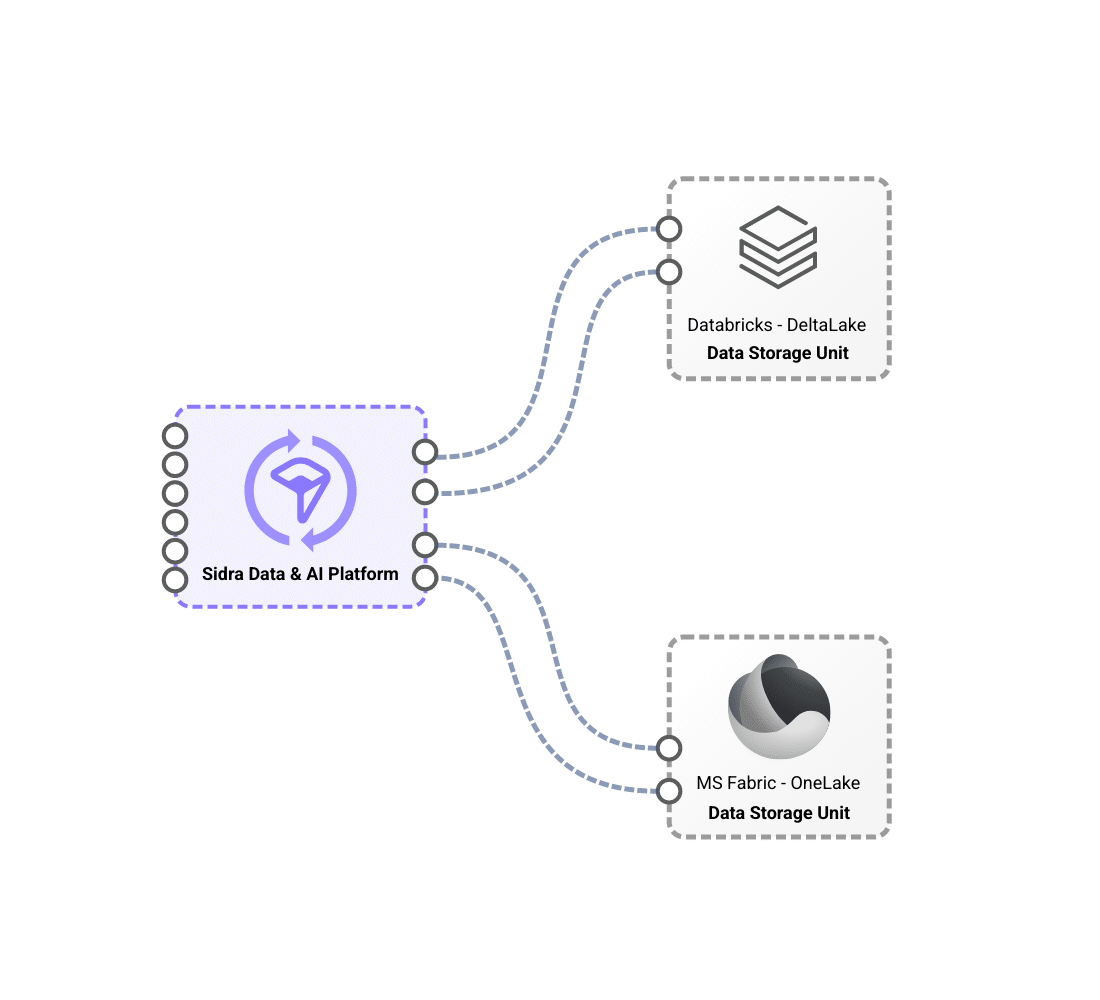
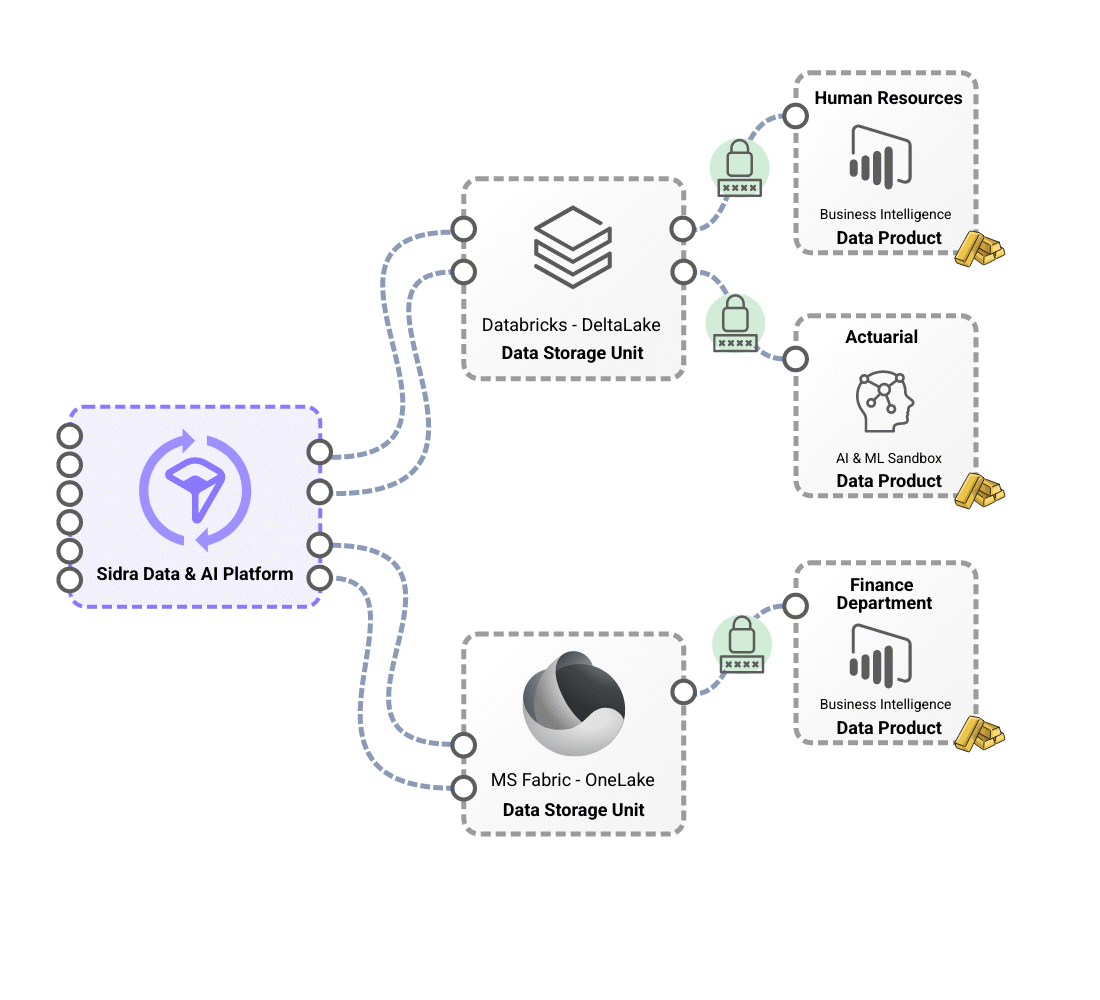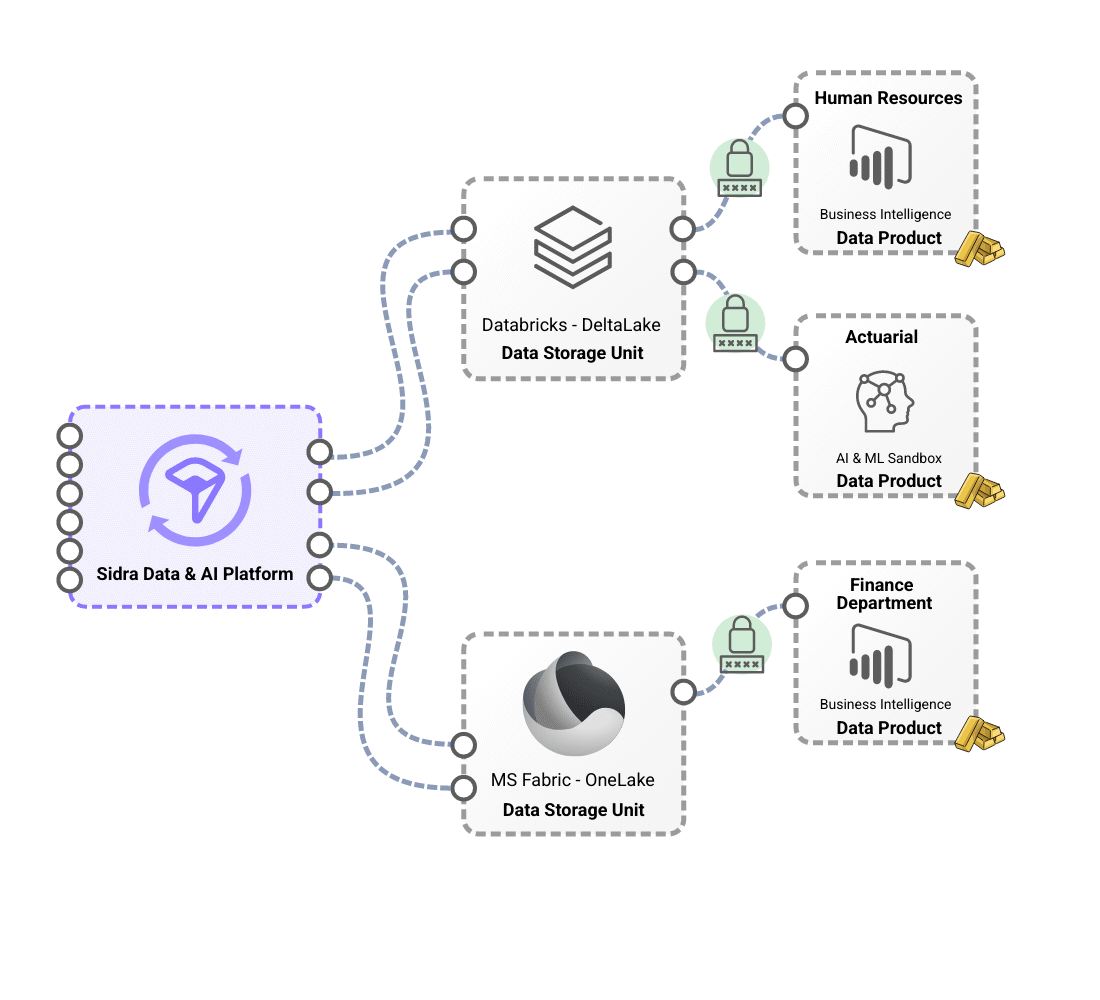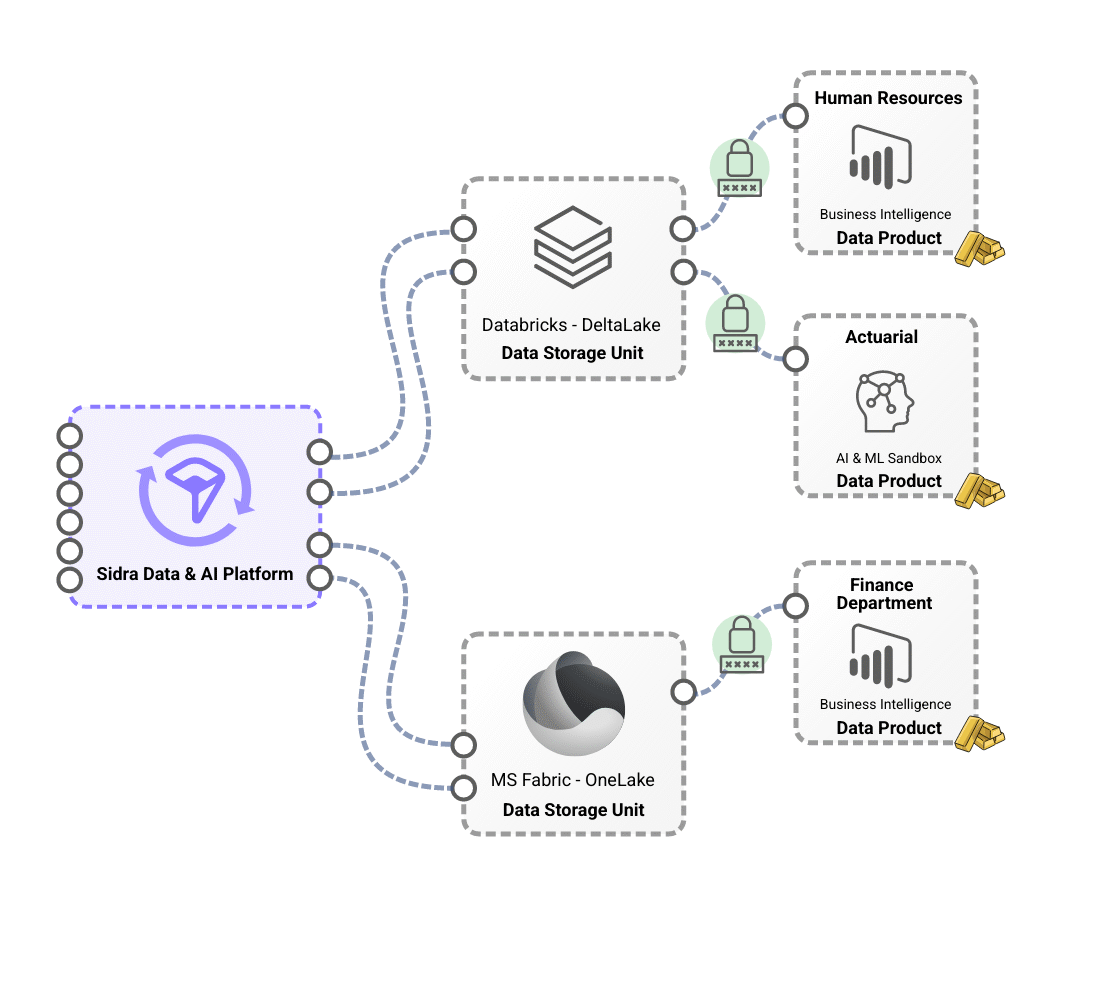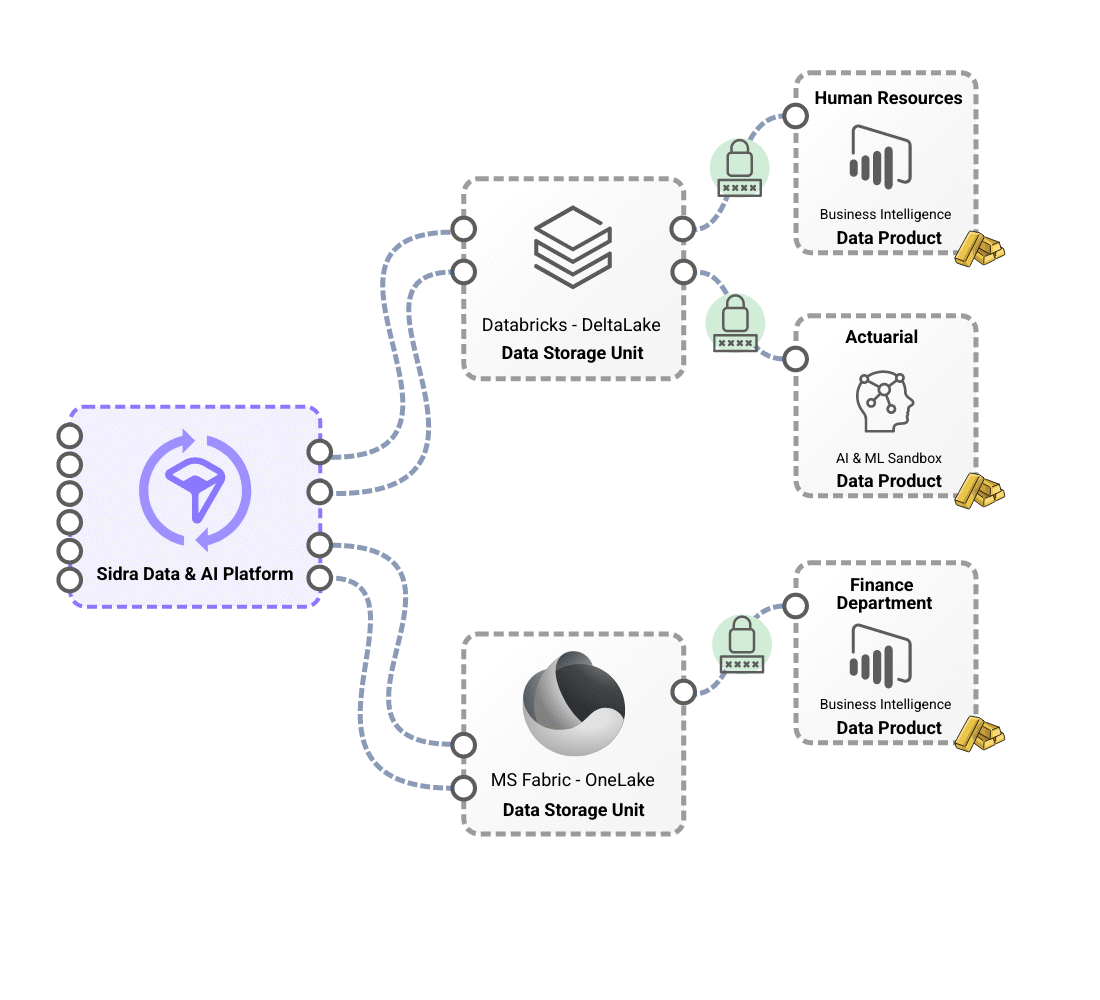
Differentiated storage contexts with Data Storage Unit, which provide technological and regulatory flexibility.
Sidra’s flexible storage model leverages Data Storage Units (DSUs) to provide technological and regulatory adaptability. These DSUs serve as the primary storage solution, optimizing performance with advanced formats like Apache Delta. They support different storage technologies, including Databricks-based and Microsoft Fabric-based DSUs, allowing organizations to tailor their infrastructure based on technical and business needs. With this approach, a single installation can host multiple DSUs with different technology stacks, ensuring seamless integration and operational efficiency.
A key advantage of this model is its ability to adapt to complex regulatory and operational requirements, enabling the deployment of multiple DSUs across different geographical regions while maintaining a unified platform. This eliminates the need for redundant systems, reducing complexity while ensuring data security and integrity. By supporting Databricks-based and Microsoft Fabric-based DSUs, Sidra empowers businesses to leverage advanced data processing capabilities while maintaining a scalable, secure, and regulatory-compliant storage architecture.
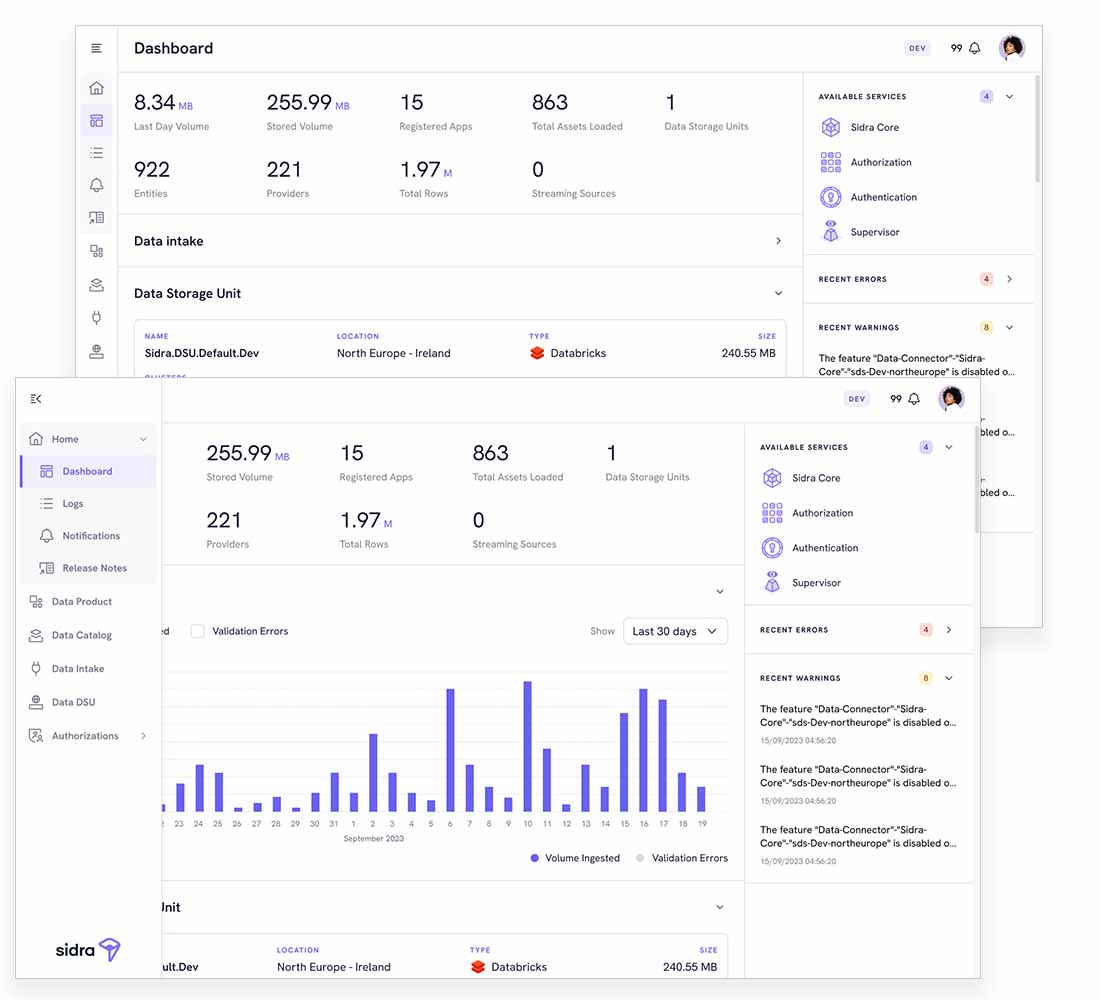
Modern interface that enables high levels of transparency and observability during each stage of the data lifecycle.
Sidra’s comprehensive web manager simplifies the setup and monitoring of all data processes, whether as standalone tasks or part of an end-to-end workflow. This interface provides real-time visibility into key processes and artifacts, allowing operators to efficiently track data movement from source to end-user. By offering full transparency and control, Sidra enables data-driven organizations to optimize operations with greater agility and accuracy, ensuring a consistent and reliable data flow.
To maintain data integrity from ingestion onward, Sidra incorporates automated verification mechanisms, including an AI-based anomaly detection engine. This system continuously monitors key attributes such as row count, data volume, and validation errors to identify potential issues before they impact business operations. Any anomalies are logged, and users receive proactive notifications for corrective actions. Additionally, Sidra includes an automatic recovery feature, allowing datasets affected by temporary system outages (e.g., Azure failures or source disruptions) to be reloaded seamlessly, ensuring data consistency, resilience, and uninterrupted business operations.
Automated governance through self-generated resource tagging, strict ownership rules and explicit-only access to data.
Sidra goes beyond simple data storage by integrating a modern data governance model that ensures security, consistency, and transparency in data management and distribution. It incorporates multiple built-in services that enrich data with key governance attributes, enabling organizations to maintain compliance and control.
The platform features self-populated lineage tracking, which automatically maps the entire journey of a data record from ingestion to final use. This allows operators and developers to quickly assess data origins, transformations, and workflows. A strict ownership model assigns clear responsibility for each dataset and data product, ensuring that access policies and restrictions are well-defined and enforceable. Additionally, full audit trails and regulatory checks track every schema change, making compliance effortless, especially for heavily regulated industries.
Sidra enhances data quality with a rule-based validation engine, allowing operators to define policies that verify data integrity before it is used. If a validation rule is breached, automated alerts notify operators, enabling quick corrective actions. This approach strengthens data reliability, governance, and compliance, ensuring that organizations can trust their data for critical business decisions.
Automatic Platform deployment and upgrade within a customizable network security context.
Sidra’s PaaS architecture acts as a cloud accelerator, enabling automated deployment of both functional resources and a secure network environment. Validated by highly regulated industries such as banking, finance, healthcare, and insurance, Sidra simplifies cloud adoption with a low-risk, high-control setup. Deployment requires only an Azure tenant and subscription, with pre-configured scripts streamlining installation. The web-based Supervisor further reduces complexity, offering a flexible and secure configuration environment tailored to each organization’s needs.
The platform supports a wide range of cloud environments, from enterprises with existing infrastructure to new entrants looking for an automated cloud setup. Once installed, Sidra is fully scalable, allowing businesses to expand functionality, install new services, and implement upgrades through the Supervisor. Its vertical scaling capabilities ensure optimal resource allocation, adapting dynamically to workload demands and enabling efficient, future-proof data management.
"On-demand deployment and configuration of domain-oriented data products, providing individual teams with an increased level of autonomy through decoupled access to data loaded in the Platform."
Modern organizations require flexible data management to support multiple operational teams, each with distinct and sometimes conflicting data needs. Sidra addresses this by decoupling data access through domain-specific data products, ensuring both agility and data integrity.
With its reverse-ETL engine, Sidra enables seamless data distribution from DSUs to individual domains by simply managing access privileges and consolidation rules. This ensures immediate availability of data, reducing delays at the project level and accelerating business-driven solutions. Additionally, by introducing an intermediate layer between data ingestion and domain-level access, Sidra prevents schema changes in source systems from disrupting workflows, keeping each domain independent and unaffected unless explicitly configured otherwise.
Sidra Data & AI Platform is powered by a robust set of core services that streamline installation, security, data quality, and automation. From deployment and access management to data validation and API generation, these services ensure a secure, scalable, and intelligent data ecosystem. Explore how Sidra simplifies complexity, enhances efficiency, and accelerates digital transformation.
The Supervisor is Sidra's platform for managing the lifecycle of installation, updating, and maintenance of the entire Sidra ecosystem. It offers both a user interface and an API to guide administrators during the initial setup, ensuring a smooth deployment. Once installed, the Supervisor allows adding new services or functionalities in Sidra according to available licenses, providing a flexible way to expand and customize the platform based on organizational needs. Beyond installation, the Supervisor centralizes update management to keep all Sidra components up to date and protected. Through its interface and API, administrators can apply patches, update versions, and monitor the status of each installed service. This centralized approach helps maintain platform consistency, reducing downtime and ensuring Sidra's operational stability.
The Authentication Service is an essential component of the Sidra ecosystem, using Keycloak, an open-source identity and access management solution, to ensure secure authentication and efficient session management. Keycloak implements OpenID Connect (OIDC) and OAuth 2.0 standards, ensuring that Sidra complies with industry best practices for identity management and authorization flows. Additionally, by integrating with Azure Active Directory, the service supports single sign-on (SSO), allowing users to seamlessly access both Sidra Core and its Data Products with their corporate credentials. Besides simplifying the login experience, the Authentication Service allows administrators to apply consistent security policies across all Sidra components. It can be configured to support multi-factor authentication (MFA), custom identity providers, and other security measures, depending on each organization's needs. This centralized approach facilitates identity management, reduces administrative burden, and strengthens Sidra's security posture.
The Authorization Service is a key component of Sidra Data & AI Platform, providing granular and flexible control over user and service access rights. Based on Balea, a framework for defining and managing authorization policies through roles and permissions, this service ensures that each entity (user or data product) only has access to permitted data and operations. It integrates seamlessly with Keycloak, the system responsible for authentication and identity management, allowing precise access rules to be applied to Sidra's data and resources. In addition to assigning roles and permissions, the Authorization Service simplifies the auditing and maintenance of security policies over time. Administrators can easily track changes and validate compliance with internal or regulatory standards. This centralized approach allows small and large organizations to scale access policies across multiple projects, ensuring secure and consistent access control throughout the Sidra ecosystem.
The Authorization Service is a key component of Sidra Data & AI Platform, providing granular and flexible control over user and service access rights. Based on Balea, a framework for defining and managing authorization policies through roles and permissions, this service ensures that each entity (user or data product) only has access to permitted data and operations. It integrates seamlessly with Keycloak, the system responsible for authentication and identity management, allowing precise access rules to be applied to Sidra's data and resources. In addition to assigning roles and permissions, the Authorization Service simplifies the auditing and maintenance of security policies over time. Administrators can easily track changes and validate compliance with internal or regulatory standards. This centralized approach allows small and large organizations to scale access policies across multiple projects, ensuring secure and consistent access control throughout the Sidra ecosystem.
The Data Quality Service offers an interactive approach to creating and applying data validation rules, ensuring consistent and reliable data ingestion. Based on the Great Expectations framework, this service compares ingested data with predefined rules to detect possible inconsistencies or anomalies. Once validation processes are completed, the service automatically generates HTML reports detailing passed tests, detected failures, and relevant metrics on overall data quality. In addition to validating incoming data, the Data Quality Service allows administrators to refine and update validation rules over time. These rules can be modified through a configuration-based interface, adapting to changing data governance requirements. By centralizing validation within Sidra, teams can quickly identify and correct issues, ensuring more accurate and reliable data for analysis and decision-making.
The API Builder Service allows automatically generating GraphQL and REST APIs for Sidra's Data Products. It analyzes providers and entities within a Data Product, facilitating the creation of endpoints without manual coding. This metadata-based approach ensures that exposed data is consistent and accessible to both internal and external consumers. In addition to generating the API, the API Builder automatically provisions the necessary infrastructure to host it within the Data Product. By handling deployment configuration, security, and integration with data pipelines, it reduces operational burden and promotes a standardized experience within the Sidra ecosystem. This combination of automation and flexibility allows organizations to quickly extend and adapt their data services in response to new needs.
In today’s fast-paced digital landscape, data-driven transformation is essential for businesses across all industries. However, many organizations face challenges such as failed data initiatives, inefficient data migrations, high infrastructure costs, and complex compliance requirements.
Sidra Data & AI Platform provides a scalable, secure, and automation-driven solution that enables organizations to unlock the full potential of their data. From real estate and legal tech to banking and telecommunications, Sidra accelerates data consolidation, AI adoption, and business intelligence initiatives with its powerful, end-to-end capabilities.
Explore how Sidra has helped leading organizations solve critical challenges, modernize their data ecosystems, and drive innovation.
Challenge: A leading real estate company in Spain struggled to build a functional data platform despite investing 1M EUR and 1.5 years with an external firm, followed by another failed attempt with an internal team.
Solution: The company engaged with Sidra, which was deployed in just a few weeks.
Outcome: Within 2 months, the company’s main user-facing website was fully powered by Sidra, providing a robust and reliable data platform.

Challenge: In 2020, the UK allowed class actions for the first time. A large UK legal firm acquired the rights to represent the Volkswagen Emissions class action and saw an opportunity to build not just case management tools, but a platform to offer class actions as a service to third parties.
Solution: Using Sidra’s Data Product building capabilities, they developed a Data Product template that provided the necessary infrastructure to launch a new class action in minutes.
Outcome: Sidra’s built-in data integration, security, compliance, and management features allowed the firm to focus on expanding their business rather than handling technical complexities.

Challenge: A leading investment management company needed to modernize its technology to provide both internal teams and end users with better tools to monitor their assets under management.
Solution: Sidra was swiftly deployed in a highly regulated Azure environment, overcoming strict compliance and security requirements. Once implemented, Sidra enabled the company to develop a web-based B2C portal for customers to analyze their assets, access meeting notes, and more. The solution went beyond traditional BI projects by leveraging Sidra’s multi-modal capabilities to extract valuable information from documents.
Outcome: The company now operates 17 Data Products built with Sidra, primarily developed by their internal teams, enhancing efficiency and data accessibility.

Challenge: A major UK construction holding was working on a large-scale initiative to consolidate critical systems across its group, including CRM, ERP, and finance systems. After two years, their data migration pilot faced technical issues and data quality problems, making it clear they would miss their targets.
Solution: By deploying Sidra and using the Data Migration template, the company leveraged a modern DataOps approach to streamline migration processes.
Outcome: The time required for "dry runs" was reduced from weeks to just 24 hours. Additionally, data quality improved significantly through Sidra’s built-in validation framework.

Challenge: A major bank in Spain aimed to improve its cloud adoption but was facing high infrastructure costs and operational inefficiencies due to its existing data platform.
Solution: The bank transitioned to Sidra and Microsoft Azure, successfully migrating its workloads, including integration with its banking mainframes. This migration enabled the adoption of modern BI and AI use cases, streamlining data management and analytics.
Outcome: By implementing Sidra, the bank improved operational efficiency and significantly reduced infrastructure costs, eliminating dependencies on expensive legacy components.

Challenge: A major telecommunications company needed to build a system to analyze physical security incidents, including access to physical locations and incidents occurring during employee travel.
Solution: The system required data consolidation and data cleaning, along with multiple access points to the information through Power BI dashboards and a web portal. The Data Marts supporting both the dashboards and the portal were accelerated using a Sidra Data Product.
Outcome: The platform has been in service for the past three years and has been actively developed by a third-party vendor, demonstrating Sidra’s adaptability for partner-led development.

Sidra’s Proof of Concept (PoC) offers organizations the opportunity to evaluate the platform’s capabilities in a real-world scenario before full implementation. For a $50,000 investment, customers gain access to a fully functional deployment, tailored to their data needs, allowing them to test Sidra’s power in data integration, governance, automation, and AI-driven insights.
If the engagement transitions into the Post-Accelerator Program, the $50,000 PoC fee is deducted from the Sidra license cost, effectively making the PoC a risk-free investment toward long-term adoption. However, if the customer decides not to proceed, the PoC fee is non-refundable. This ensures organizations can confidently explore Sidra’s impact before making a full commitment.